Maps
Mini Google Maps
React/JS, Java | Spring 2021
This project was a full-stack primitive Google Maps app to render an interactive map of Rhode Island. I pair-programmed an application with the following functionality:
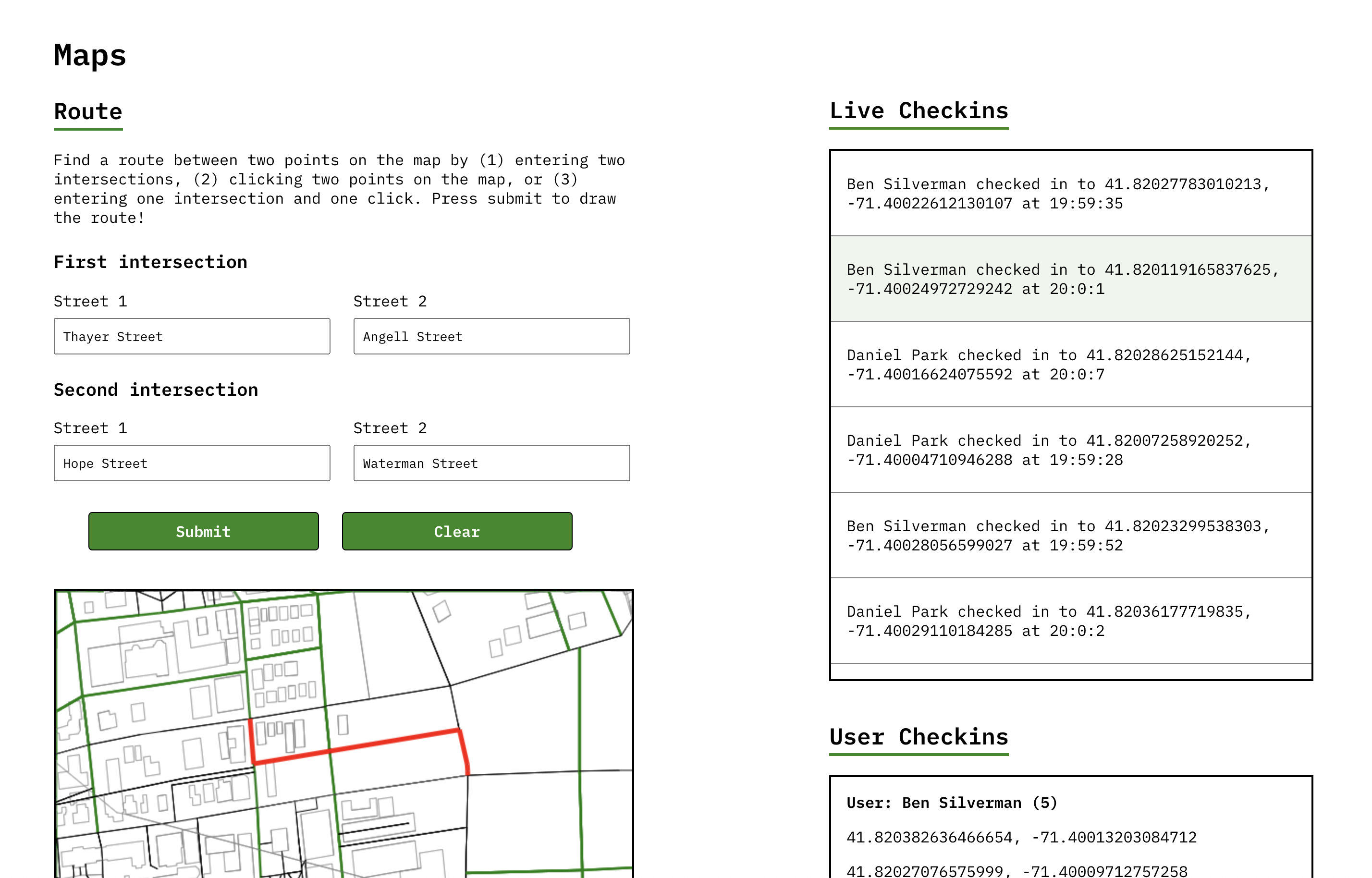
- Navigating the shortest path between two points (Dijkstra's/A* Algorithm)
- Finding the nearest locations of interest (K-Nearest Neighbors Algorithm)
- Loading and parsing map data
- Zooming and panning the map UI
- Displaying live check-ins from multiple users
My responsibilities included designing data structures to represent the map, implementing the K-Nearest Neighbors algorithm, parsing map data, integrating multi-threading, handling zooming/panning, and designing the user interface.
Technical features
Data Structure Design
First, my partner and I had a high-level discussion to determine how to represent our map data. Because we needed to represent both intersections and streets, we decided to create a directed graph with nodes as intersections and edges as streets. We then used the graph for our Dijkstra's and A* implementation to find the shortest paths between nodes.
Although a graph was great for charting the shortest paths between nodes, we knew it wasn't ideal for finding neighboring nodes. We'd potentially have to search the entire graph to find our target node (which wouldn't scale well for larger maps). Additionally, since we represented nodes as (x, y) coordinates, we needed a data structure that could handle calculating distances on multiple dimensions. We thus decided to represent the map as a K-D tree in addition to a directed graph -- this allowed us to efficiently implement our K-Nearest Neighbors Algorithm by cutting the search time.


K-Nearest Neighbors Algorithm
To implement the K-Nearest Neighbors Algorithm, I created a KD Tree class. Because I knew our KD Tree implementation might be used for future projects, I kept it extensible by creating an abstract KD Node class and a KD Node comparator. This let me design a maps-specific KD Node (where each node has 2 dimensions) while preserving node functionality (calculating Euclidean distance, etc.) for different KD Node implementations -- for example, nodes with x, y, and z coordinates.
Parsing
Then, I created a CSV parser to process map data. I also created a REPL to take in user commands.
The CSV parser contained two methods. One converted CSVs to an ArrayList of Strings, where each ArrayList represented a CSV row. The other validated each CSV to make sure (1) the CSV filepath was a valid file, and (2) security permissions were enabled.
I decided to split the REPL into a REPL class and a Methods interface. The REPL class parsed and execute valid inputs, while the Methods interface defined a generic function for executing each command. I then created a class implementing the Methods interface, where I defined the logic for valid Maps commands (eg. finding K-nearest neighbors, loading maps data, etc.). This was designed to keep the REPL as extensible as possible, since it didn't tie the REPL to project-specific implementations (meaning I could reuse it in the future).
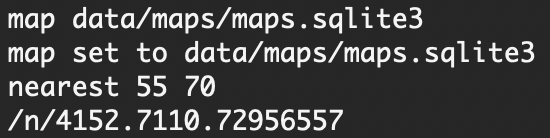
Zooming and Panning
The next step was building the frontend. I designed the UI in React and displayed the map with JavaScript canvas, using React hooks to update the map state each time the user zoomed/panned. To re-render the map with each user interaction, I used the delta from the user's mouse movements to calculate a new set of coordinates relative to the canvas dimensions.
I knew that rendering the whole map would be inefficient, especially if we reloaded the entire map each time the user zoomed/panned. Thus, to optimize loading time, I decided to divide map coordinates into a tiled grid, caching map tiles with the Google Guava Cache API. This optimized client-side rendering by tracking which map sections were already rendered, allowing me to retrieve map sections quickly.
Multi-Threading
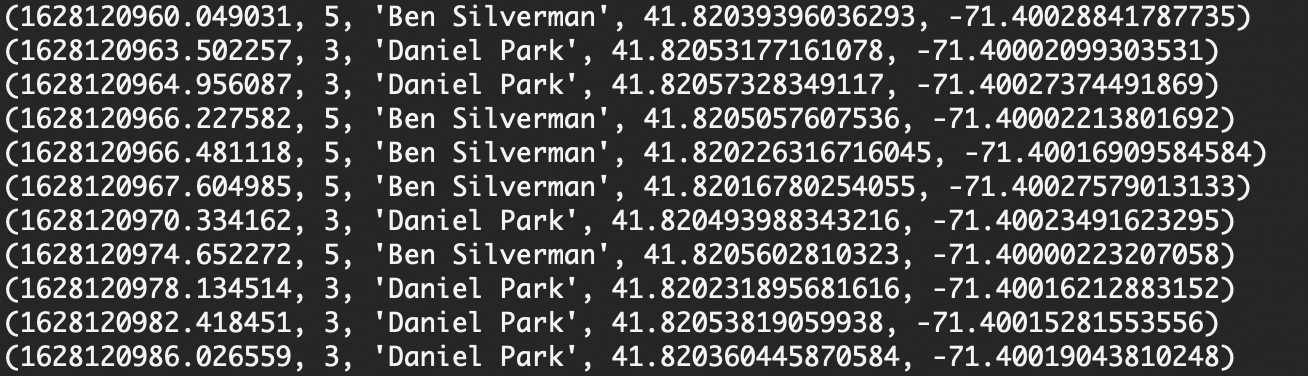
Finally, I implemented multi-threading to display live check-ins from multiple users. One thread ran our backend server to handle user commands and map rendering; the other made continuous calls to a server with user check-ins. This enriched the UI by letting me display both a live feed of user check-ins and the interactive map while executing separate backend calls simultaneously.
Conclusion
The hardest -- and my favorite -- part of this project was the creative freedom of building an application from scratch. My partner and I weighed countless implementations (should we use a directed or undirected graph? What key-value pairs should we store in the cache?). Debating pros and cons gave us a deeper understanding of each option, which gave us more confidence when we decided on a solution. I also enjoyed working both individually and collaboratively: my partner and I often brainstormed separately and reconvened to share ideas, and I liked seeing how we uniquely approached the same challenge.
I also enjoyed applying software engineering principles. Maps tested my knowledge of data structures beyond runtimes and space complexities, and I enjoyed implementing new-but-familiar structures such as KD trees (which were similar to the binary trees I learned in my intro CS classes). I learned how to organize applications on a high level, such as designing abstract classes for modularity and interfaces for extensibility. I also discovered the importance of low-level thinking; for example, I realized optimizing one SQL query drastically reduced data retrieval time, which improved both client-side rendering and overall UX.
Overall, this project was a great taste of software engineering. I gained experience designing an application from the ground up, and I practiced using new technologies like JavaScript canvas and Guava cache. I learned how to apply software engineering principles, and I gained a better understanding of modern technologies and libraries. Above all, I enjoyed working in a team -- two heads are always better than one!