Search
Wiki Search Engine
Scala | Spring 2020
For my final project in Data Structures and Algorithms, I pair-programmed a Scala search engine indexing and querying XML wiki files. My responsibilities included implementing TF-IDF scoring (Term Frequency-Inverse Document Frequency), the PageRank algorithm, an indexer, and a querier.
Due to Brown’s collaboration policy, I cannot post the code for Search online. However, it is available upon request.
Technical features
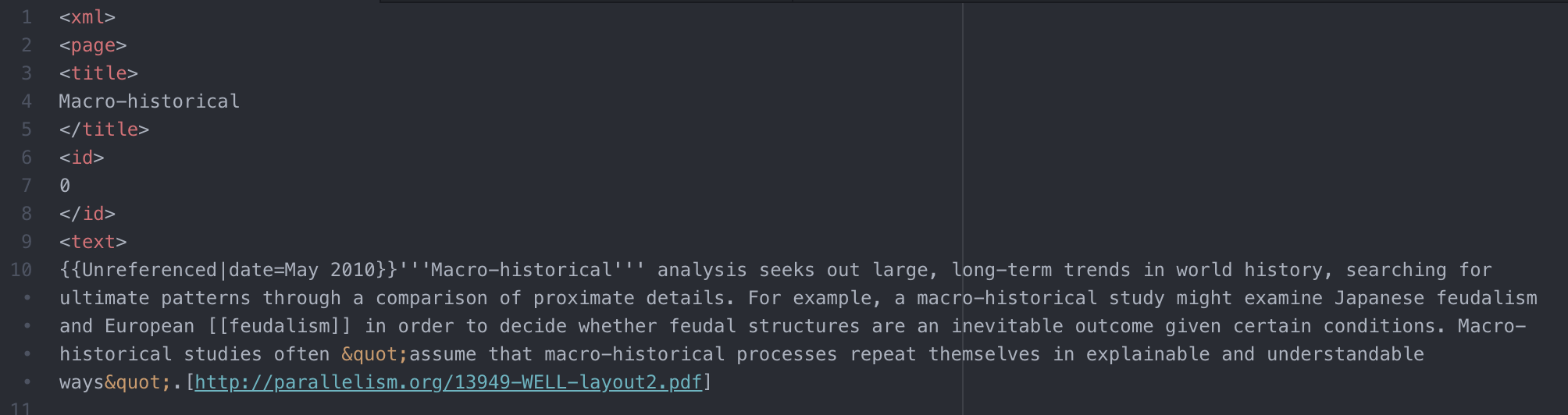
Parsing XML Files
The first step in building our search engine was to reduce XML files to essential information. First, I parsed each wiki by extracting the text between XML tags. Then, I tokenized the text with a Regex, splitting on punctuation and whitespace to separate words and numbers. Additionally, I removed unessential words (such as “the” or “and”) that didn’t contribute information to search results. Finally, I reduced words to their bases — for example, cutting “sleeping” to “sleep” — to pare down information as much as possible. We repeated this process for queries.
TF-IDF and PageRank
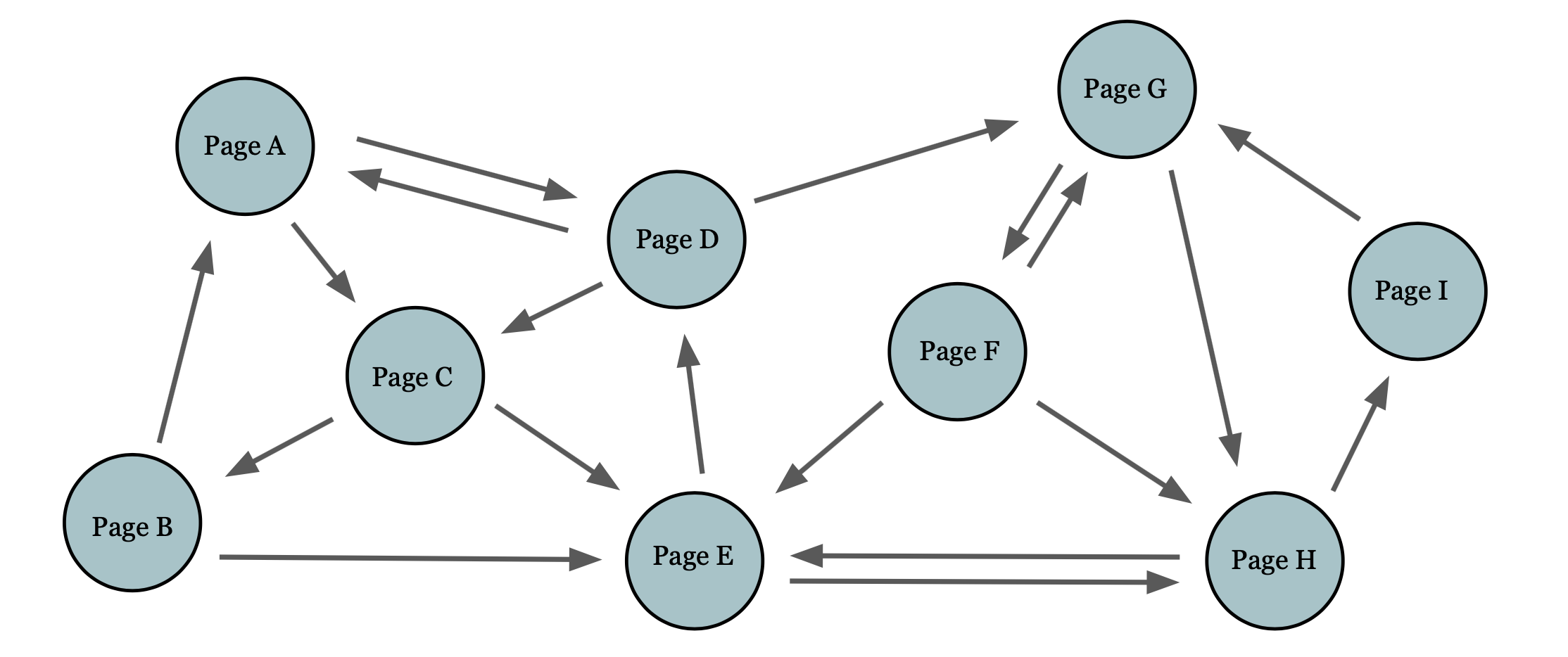
After reducing wikis and queries to essential information, I used TF-IDF scoring -- which ranks pages based on text — to calculate the relevance score of each page to a user query. I also used the PageRank algorithm — which ranks pages based on page-to-page links — to assign each page a weight. The higher the TF-IDF score and PageRank weight, the more “authority” the page carried, and thus the more relevant it would be to a query. We then calculated and stored each score in a separate data structure.
One challenge I ran into was time-space efficiency. For big XML files, our goal was to make the indexer run in 1 hour with 2 GB of memory. My initial design for data storage utilized a 2D array, where each row represented a page and each column represented the TF-IDF/PageRank score for a term. However, this was highly inefficient, since each lookup took O(n-squared) time. I thus replaced the 2D array with a hashmap, which has a constant lookup. I also set unused objects to null, which were removed by the JVM for garbage collection. Finally, I relocated code to modular methods to prevent unnecessary calculations. This reduced our space usage greatly, and we were able to process a 216.5 MB wiki within the given constraints.
Querying
Finally, we connected our indexer to the querier, which included a REPL for user-inputted search queries. In the querier, I used the hashmaps from the indexer to look up the score for each page; then, my partner and I implemented a priority queue to return the top ten relevant pages for a given query.


Conclusion
The hardest part of this project was definitely optimizing time-space efficiency. Once my partner and I got a working indexer, we had to review every line of code to discuss tradeoffs for each data structure, such as lookup, deletion, and insertion. In some cases, we had to create our own data structures. While difficult, this helped us gain a better understanding of the data structures we’d learned in class.
Another challenge was implementing TF-IDF scoring and the PageRank algorithm. While we were given a rough outline of how TF-IDF and PageRank worked, we needed to tailor our implementation based on the data structures we used. It took a lot of trial and error to capture the essence of each algorithm with our implementation, but the payoff was that much sweeter when it worked.
Overall, this project was a huge success. I learned how to choose data structures based on specific software needs, and I gained much more confidence analyzing time-space efficiency. I also learned how to implement algorithms, and I gained a new appreciation for elegant code and elegant computational thinking. And finally, I learned how to build a search engine — how cool is that!